
Fundamentals of Programming #1: Beginning
Permalink{kind=link}
This is the first article of The Fundamentals of Programming Using C series. In this article, we are going to show you some useful concepts about the programming world. We will start by using pseudocode (explained below), advancing gradually until we reach the desired language: C.
Programming Languages
Just like any human language, a programming language allows us to communicate. Not with humans, but with computers or any other computerized system. Programming languages are made of a “grammar” which contains the basic syntax rules of that language. Using those rules, we can communicate orders to a computer, it means, teach it how to do something. That is how programs are made.
Syntactic rules is a set of must-follow rules that indicate how to structure the code, that is, how to build it.
There are numerous programming languages: some with a general purpose, it means, without having a specific purpose. The language C is one example of that kind of languages. But there are also languages created inside a specific domain like the Wolfram Language, which is a domain specific language, multi-paradigm (we will talk about this later) language, dedicated to math field.
Algorithms
It is important to comprehend some basic concepts which are going to be essencial in your whole journey through the world of programming. Thus, you’ll start by understanding what algorithms are because you will always be in contact with them.
Algorithms are finite, well defined sequences of instruction that can be performed by computers, automatons or even humans.
Let’s get an example from our day to day: the process of cooking something is an algorithm. First, we search for a recipe, then we follow the instructions found on that recipe. That recipe is the key, is the algorithm.
The algorithms can be represented in many ways. We will approach two of them: flowcharts and pseudocode . These two representations of algorithms are essential before writing real code; it may help to save time because this process reduces the margin of error of the development process.
We don’t have to draw a flowchart and write the algorithm pseudocode in every single case. Sometimes, only one is enough. This depends on the working method of the developer/team.
Flowcharts and pseudocode are universal ways to represent an algorithm: they don’t depend on any programming language. So, they are good for sharing with other developers.
Flowcharts
Let’s now see the first way to represent algorithms, the flowcharts.
A flowchart is a graphical representation of an algorithm that uses symbols to demonstrate which processes need to be executed in each step.
There are some advantages of creating flowcharts:
- they are easy to create;
- they are easily shared; and
- they help to create mental models.
A flowchart may use a lot of symbols, but we will only talk about the basic ones to comprehend how flowcharts work. You may visualize them in the picture below.
Pseudocode
Another way, more similar to the final code, to represent an algorithm, is the use of pseudocode. Thus, it comes after a flowchart.
Pseudocode is a way to represent algorithms that is more similar to programming languages. But instead, it used the native language of the user so it can be easily understood for those who don’t have no knowledge about the syntax of a programming language.
Let’s take a look at this piece of pseudocode:
BEGIN
VARIABLE CHARACTER recipe <- getRecipe()
IF haveIngredients(recipe) == true THEN
makeCake()
ELSE
buyIngredients()
makeCake()
ENDIF
END
The previous code is simple to understand: the pseudocode uses our natural language so it can be easily comprehended. In this moment, I ask you to think about the expressions that end with () as commands.
An algorithm is any order or instruction given to a computer or any other automatized machine. The previous algorithm could be graphically represented as:
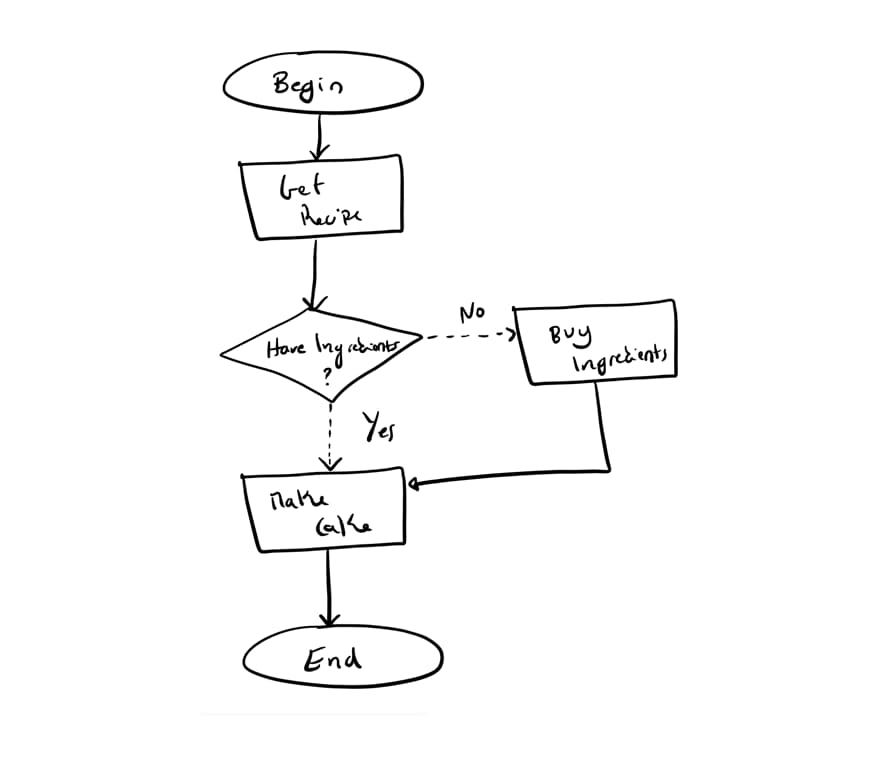
As you can see, it’s easy to understand. Both pseudocode and flowcharts.